気になるのが、選挙報道です。報道各社は、新聞やテレビだけでなく、最近ではネット選挙報道にも力を入れており、選挙そのものとは別に、これらを吟味するのも結構楽しかったりします。
昨年の衆院選では、天下無双の質問力でなみいる政治家を一網打尽、栄えあるギャラクシー賞を受賞した池上彰氏による選挙特番が、民報選挙特番の視聴率No.1を獲得しただけでなく、Yahooが実施したオンラインアンケートでも1位を記録するなど、「池上無双」としてネット上でも話題となりました。
Googleトレンドによると、衆院選のあった2012年12月、「選挙 池上」の検索頻度(49ポイント)は、自社サイトでボートマッチアプリを展開した「選挙 毎日」(毎日新聞、16ポイント)、ビリオメディアを展開した「選挙 朝日」(朝日新聞、24ポイント)を軽く上回り、ネット選挙報道の雄「選挙 Yahoo」(51ポイント)に肉薄、ネット上でも注目されていたことがわかります。「テレビの影響力は大きい」のはわかりますが、「選挙 古館」や「選挙 TBS」が圏外にあったことから、「選挙 池上」のネット上での強さは一歩抜けていた、と言い切っても良いのではないでしょうか。
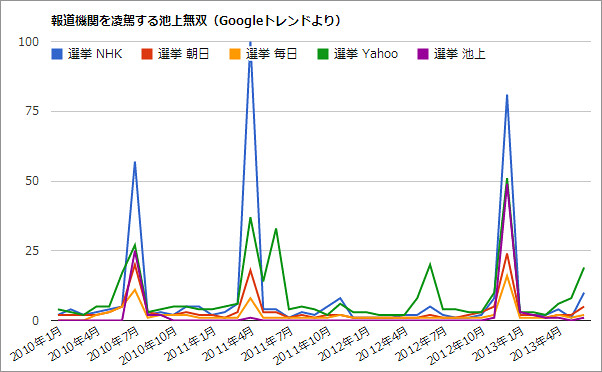
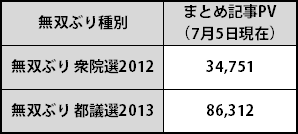
先月の都議選時に放映されたMXテレビでの無双ぶりをまとめた記事は、放映範囲が限定されていた渇望感からか、昨年の衆院選時の無双ぶりをまとめた記事を超えるアクセス数をたたき出すなど、その勢いはいまだ衰えていません。
今回の参院選、池上特番はどこまで話題をさらうのか。
一方、これを迎え撃つ報道各社は、ネット選挙報道に力を入れてきています。前回の衆院選、新聞社対決を制したのは朝日新聞、2位は毎日新聞でした。
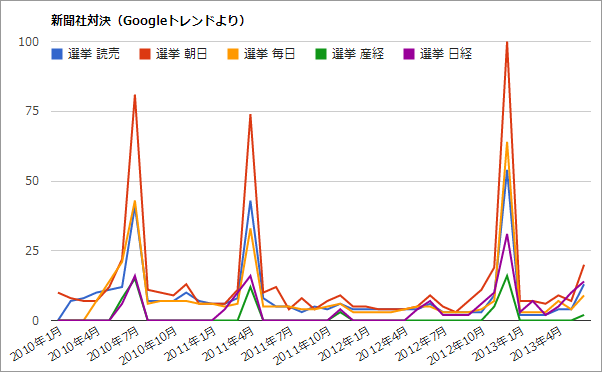
その両社、今回の参院選では、朝日新聞は東大の谷口研究室と、毎日新聞は立命館大学の西田亮介氏と、それぞれタッグを組み、特設サイトを設置してツイッター分析やボートマッチアプリを展開、いままさに熱い選挙報道を繰り広げています。
ネット選挙報道の本命NHK。じりじりと選挙報道でもプレゼンスを高めるYahoo。ツートップに割り込まんとする池上特番。朝日新聞と毎日新聞はどこまで食い込めるか――。選挙報道における仁義なきオンラインアテンション争奪戦の結果はいかに。
各特設サイトトップページのシェア数について、公示日(7月4日)の段階では、Facebookの1位が池上特番、Twitterの1位が朝日新聞、そしてはてブの1位が毎日新聞、となっていました。が、ほとんど差はなく、がっぷり四つといったところでしょうか。
 ※シェア数は公示日(7月4日)の午後6時にGoogleChromeのプラグインで確認
※シェア数は公示日(7月4日)の午後6時にGoogleChromeのプラグインで確認
※[*]NHKとYahooは選挙共通サイトの(今回の参院選で新たにつくられたわけではない)ため、参考値

※[*]NHKとYahooは選挙共通サイトの(今回の参院選で新たにつくられたわけではない)ため、参考値
投票日となる7月21日は、粛々と投票を済ませ、選挙特番のはじまる夜8時を待ちたいと思います。